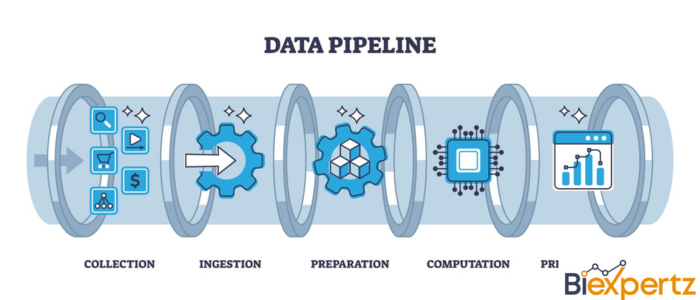
As data-driven decisions become the treasure of modern business strategies, the tools and techniques for managing data efficiently have gained popularity. One such tool is the data pipeline, a vital framework for handling and processing large volumes of data.
Hundreds of businesses depend on their business data and the increased awareness of its importance. It only makes sense for other businesses to look into their own data and see where they are potentially lacking and create more informed decision-making for revenue-driven results. Results that actually move the business up the graph in terms of their growth, fame, revenue, and importance.
In this article, we’ll explore what data pipelines are, their importance, core concepts, challenges, and the role of Microsoft Fabric in simplifying them.
What Are Data Pipelines?
A data pipeline is a series of processes or stages through which raw data flows, gets processed, and becomes usable for analysis or other purposes. It acts as a line for moving data from one system to another while performing transformations, aggregations, or other modifications. Data pipelines are mandatory for ingesting, processing, and integrating data from diverse sources into storage systems like databases or data lakes.
For example, a pipeline might pull user data from a website, clean and validate it, aggregate relevant metrics, and store the results in a dashboard for business analysts. These pipelines can work in real-time or batch modes, depending on the use case.
Read more: The Significance of Data Analytics for SaaS User Experience
Common Uses of Data Pipelines
While there are many uses for data pipelines, here, we will discuss some of the most common uses of data pipelines along with their examples.
1. Data Integration
Data pipelines serve as a bridge between diverse systems, allowing seamless integration of information from multiple sources such as CRM systems, ERP platforms, IoT devices, or third-party APIs. They consolidate data into a unified storage environment, such as a data warehouse or a data lake, for downstream applications like analytics or reporting.
Example: A retail company might use a data pipeline to integrate data from its eCommerce platform, point-of-sale systems, and inventory management software into a centralized dashboard. This unified view allows the business to track inventory levels, monitor sales trends, and make better decisions about stock replenishment.
2. Data Transformation
Data pipelines prepare raw data for analysis by cleaning, improving, or standardizing it. This process might involve tasks like removing duplicates, converting formats, filling in missing values, or aggregating data for easier consumption. Transformation makes sure that the data is compatible with the target system and meets analytical or operational requirements.
Example: In the financial industry, a bank might receive transaction data from multiple branches in various formats. A data pipeline can transform these datasets into a consistent format, validate them for accuracy, and compute metrics like total transaction volume by region, allowing the bank to analyze performance across branches.
3. Real-Time Analytics
Data pipelines allow organizations to process and analyze streaming data as it is generated. This capability supports time-sensitive use cases such as fraud detection, personalized marketing, or operational monitoring. Real-time pipelines often rely on technologies like Apache Kafka or Microsoft Azure Stream Analytics.
Example: A ridesharing company might use real-time data pipelines to analyze GPS data from its drivers and match them with nearby passengers instantly. This makes sure of efficient ride allocation and provides customers with real-time tracking.
4. ETL/ELT Workflows
Pipelines automate the Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT) processes, allowing structured data preparation for analytics. These workflows are critical for feeding data warehouses with curated, analysis-ready data.
Example: A media company that collects the daily viewing habits of its users might use an ETL pipeline to extract data from its content servers, transform it to calculate viewer engagement metrics, and load it into a reporting tool like Power BI for business insights.
5. Machine Learning
Data pipelines are important in machine learning (ML) as they prepare training and inference datasets. Pipelines preprocess data by scaling, normalizing, or augmenting it to improve model performance and reliability.
Example: An eCommerce platform might use a pipeline to preprocess customer purchase data, preparing it for an ML model that predicts customer preferences. The model can then generate personalized recommendations in real-time, improving user experience.
Learn more about how data can benefit you: Advantages of Power BI for Small Businesses.
Why Are Data Pipelines Important?
Data pipelines are not simply operational tools; they serve as a foundation for modern data strategies. They have transformed the way businesses move ahead in their strategies and more. Here are seven reasons why they are required:
1. Automation of Data Workflows
Manually collecting, cleaning, and transferring data can be labor-intensive and error-prone. Data pipelines automate these repetitive tasks, making sure of consistent and efficient data handling. This frees up time for data professionals to focus on more complex analysis and strategic decisions. Automation also minimizes human error, ensuring the integrity of data across processes. In a fast-paced environment, automated workflows enable quicker and more reliable access to actionable insights.
2. Scalability
As businesses grow, so does the volume of their data. Data pipelines are designed to scale horizontally and vertically, accommodating increased data loads without compromising performance. For instance, pipelines can process data from thousands of IoT devices or expand to include new data sources seamlessly. This scalability makes sure that organizations remain agile and adaptable as their data needs evolve. By combining scalable tools like Microsoft Fabric, businesses can handle petabyte-scale workloads efficiently.
3. Real-Time Processing
Modern businesses demand instant insights, whether for personalized customer experiences or operational efficiency. Data pipelines facilitate real-time data processing, allowing companies to react to events as they happen. Examples include detecting fraudulent transactions or updating inventory systems in real-time. This capability supports time-sensitive decisions and improves customer satisfaction. Real-time data pipelines benefit from technologies like streaming analytics for continuous monitoring and alerting.
4. Data Quality and Integrity
Data pipelines incorporate validation and cleansing steps to make sure that the processed data meets predefined quality standards. High-quality data is important for accurate analytics and informed decision-making. These pipelines can detect anomalies, remove duplicates, and handle missing values effectively. By maintaining data integrity, businesses avoid costly errors and improve the reliability of insights derived from their datasets. Consistent quality also builds stakeholder trust in data-driven outcomes.
5. Centralization of Data
Organizations often have data spread across multiple systems, making it challenging to get a unified view. Data pipelines consolidate disparate datasets into centralized storage solutions, such as data lakes or warehouses. Centralized data enables cross-functional analytics and promotes collaboration between departments. This integration reduces data silos and provides a single source of truth for decision-making. Centralized access is crucial for advanced use cases like machine learning and predictive analytics.
6. Cost Efficiency
Efficient data pipelines reduce the need for manual interventions and repetitive storage. By optimizing how data is processed and transferred, pipelines cut operational costs significantly. Organizations can also avoid over-provisioning resources, as pipelines are designed to work efficiently at scale. Cost savings are particularly evident in cloud-based environments, where usage-based pricing models reward optimized workflows. A simplified data pipeline architecture reduces the total cost of ownership for data infrastructure.
7. Compliance and Security
In today’s regulatory landscape, making sure data compliance is important. Data pipelines can include encryption, masking, and logging steps to protect sensitive information. They help organizations adhere to regulations like GDPR, HIPAA, or CCPA by enforcing governance policies across data flows. Automated compliance checks reduce risks associated with breaches or non-compliance penalties. By embedding security measures in data pipelines, organizations build trust with their customers and regulators alike.
Learn more: Top Data Analyst Skills You Should Know
The Core Concepts of Data Pipelines
Understanding data pipelines requires familiarity with their key components. There are three core concepts for data pipelines:
1. Activity
An activity represents a step within a data pipeline, such as data extraction, transformation, or loading (ETL). Each activity performs a specific task, such as copying data, running scripts, or integrating APIs. Activities can be sequenced or parallelized to achieve complex workflows.
For example, one activity might clean raw data while another turns it into meaningful metrics. Activities are the building blocks of a pipeline, making sure of modularity and scalability.
2. Parameters
Parameters are dynamic inputs that allow for the customization of pipelines. Instead of hardcoding values, parameters allow reusability and flexibility in pipeline configurations. For instance, a pipeline extracting data from multiple sources can use parameters to specify file paths, dates, or source names. This reduces duplication of effort and makes pipelines more adaptable to changing requirements. By using parameters, teams can manage large-scale data workflows efficiently with minimal manual intervention.
3. Copy Data Activity
The Copy Data Activity is a fundamental feature in tools like Microsoft Fabric, allowing data movement from source to destination. This activity supports various formats and protocols, allowing seamless data integration. It handles data extraction, transformation (e.g., mapping columns), and loading into target systems. Whether moving data to a cloud-based storage or an on-premise database, this activity makes sure of high performance and reliability. The Copy Data Activity is essential for creating strong, end-to-end pipelines.
Learn more: A Guide for Creating Strong Power BI Dashboard Design
Common Challenges and Tips
While most of these metrics and definitions may sound simple, when it comes to implementing these strategies, the struggle can be real. This is why most businesses opt to hire professional data analysts and data scientists to help with data work. However, to have a basic understanding of this, this section will cover the basic challenges that people face in this field.
Challenges
Data pipelines are not without their hurdles. One major challenge is data complexity. With diverse formats, sources, and schemas, integrating data can be cumbersome. Errors during transformation or incompatibilities in schemas often result in delays. Additionally, scaling pipelines to handle growing data volumes without degrading performance is a persistent issue. Monitoring and troubleshooting failures in real-time pipelines can also be resource-intensive.
Another challenge is data governance. Pipelines must stick to organizational policies regarding access control, privacy, and compliance. Overlooking governance can lead to security vulnerabilities and regulatory penalties. Moreover, poorly documented pipelines can make maintenance and debugging difficult, especially as systems evolve.
Tips for Overcoming Challenges
1. Standardize Processes
Use standardized formats, naming conventions, and tools to reduce complexity and improve consistency across pipelines.
2. Invest in Monitoring Tools
Implement monitoring solutions that provide real-time insights into pipeline performance and failures.
3. Automate Governance
Benefit from automation in implementing data governance policies, providing compliance with minimal effort.
4. Focus on Scalability
Use cloud-based platforms like Microsoft Fabric to build scalable and resilient pipelines that grow with your data needs.
5. Document Pipelines
Maintain clear and comprehensive documentation to streamline maintenance and facilitate knowledge sharing.
Taking Your Data Pipeline Strategy to the Next Level
Implementing a well-designed data pipeline is essential for modern businesses to manage data efficiently and derive actionable insights. By automating workflows, making sure of data quality, and scaling seamlessly, pipelines empower organizations to transform raw data into valuable assets. Benefitting from the best practices and tools like Microsoft Fabric can help address common challenges like complexity and governance while maximizing pipeline performance.
Key Takeaways
Essential Success Factors for Data Pipelines
- Automated and scalable data workflows
- Real-time processing and seamless integration
- Guaranteed data quality and compliance
- Cost-effective and efficient operations
- Strong monitoring and troubleshooting
Action Steps to Get Started
Initial Setup
- Identify and analyze data sources.
- Define pipeline requirements and workflows.
- Select a suitable platform like Microsoft Fabric.
- Design processes for data cleaning, transformation, and loading.
- Establish security protocols and compliance measures.
Pipeline Execution
- Set up real-time monitoring systems.
- Optimize pipeline performance regularly.
- Address bottlenecks with dynamic scaling.
- Conduct periodic audits to ensure data governance.
“Success in data pipelines comes from consistent planning, automation, and optimization. With the right tools, every pipeline execution can unlock the power of your data ecosystem.”
Next Steps for Your Data Strategy
Ready to transform your business’s data pipeline operations? Here’s how BiExpertz can help:
- Design and implement custom data pipelines.
- Optimize your workflows for scalability and performance.
- Improved data quality and compliance processes.
- Force platforms like Microsoft Fabric to maximize ROI.
- Provide expert support and ongoing maintenance.
Contact BiExpertz Today
Let us simplify your data workflows and empower your organization to unlock the full potential of its data. At BiExpertz, we specialize in creating tailored data pipeline solutions that integrate seamlessly with your existing systems, improve performance, and ensure compliance. Whether you’re scaling operations, optimizing workflows, or leveraging cutting-edge platforms like Microsoft Fabric, our experts are here to guide you every step of the way.